A transversal-logic-equipped surface code architecture for readout-constrained spin qubits
(under review)
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
Abstract
Spin qubits in silicon quantum dot arrays are a promising quantum computation platform for long-term scalability due to their small qubit footprint and compatibility with advanced semiconductor manufacturing. However, spin qubit devices face a key architectural bottleneck: the large physical footprint of readout components relative to qubits prevents a dense layout where all qubits can be measured simultaneously, complicating the implementation of quantum error correction. This challenge is offset by the platform’s unique rapid shuttling capability, which can be used to transport qubits to distant readout ports. In this work, we explore the design constraints and capabilities of spin qubits in silicon and propose the SNAQ (Shuttling-capable Narrow Array of spin Qubits) surface code architecture, which relaxes the 1:1 readout-to-qubit assumption by leveraging spin shuttling to time-multiplex ancilla qubit initialization and readout. Our analysis shows that, given sufficiently high (experimentally demonstrated) qubit coherence times, SNAQ delivers an orders-of-magnitude reduction in chip area per logical qubit. Additionally, by using a denser grid of physical qubits, SNAQ enables fast transversal logic for short-distance logical operations, achieving 4.0-22.3x improvement in local logical clock speed while still supporting global operations via lattice surgery. This translates to a 57-60% reduction in spacetime cost of 15-to-1 magic state distillation, a key fault-tolerant subroutine. Our work pinpoints critical hardware metrics and provides a compelling path toward high-performance fault-tolerant computation on near-term-manufacturable spin qubit arrays.
[.pdf] [arXiv]Selected Figures

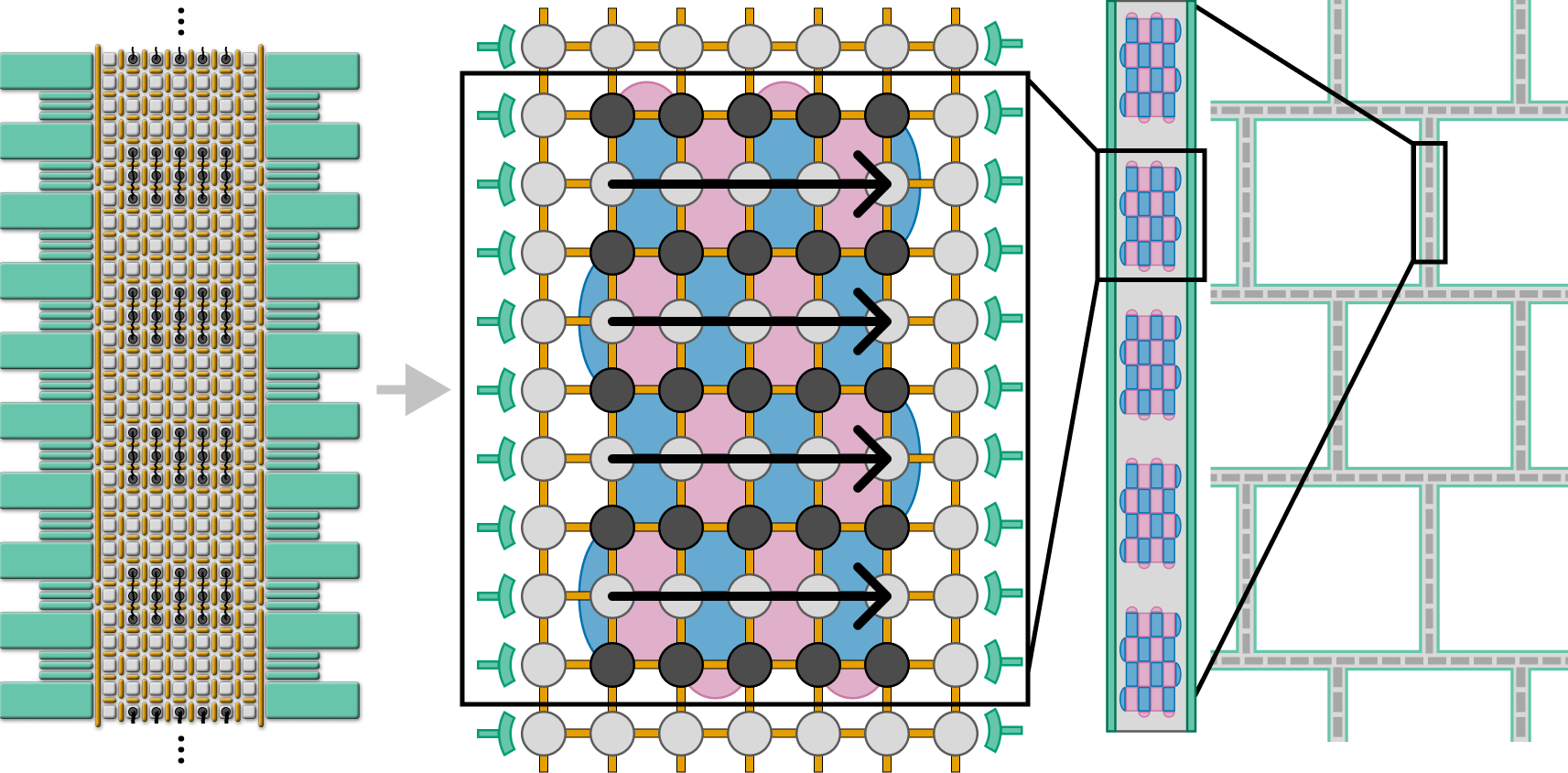
Figure 1. (a) Depiction of a possible implementation of a narrow 7-dot-wide array of quantum dots, analogous to similar devices fabricated by Intel and HRL [27]-[29]. Electrons (black) are held in place at the plunger gates (light gray) and can interact with their neighbors (or shuttle to adjacent plungers) by manipulating the voltages on the barrier gates (orange). Single-electron transistors (green) allow for qubit readout on the two sides of the array. (b) SNAQ achieves similar performance to baselines while improving chip area efficiency and wiring efficiency. (c) SNAQ avoids the downside of a longer syndrome extraction cycle by enabling transversal CNOTs (tCNOTs), achieving significantly faster logical clock speeds compared to lattice-surgery-based approaches.
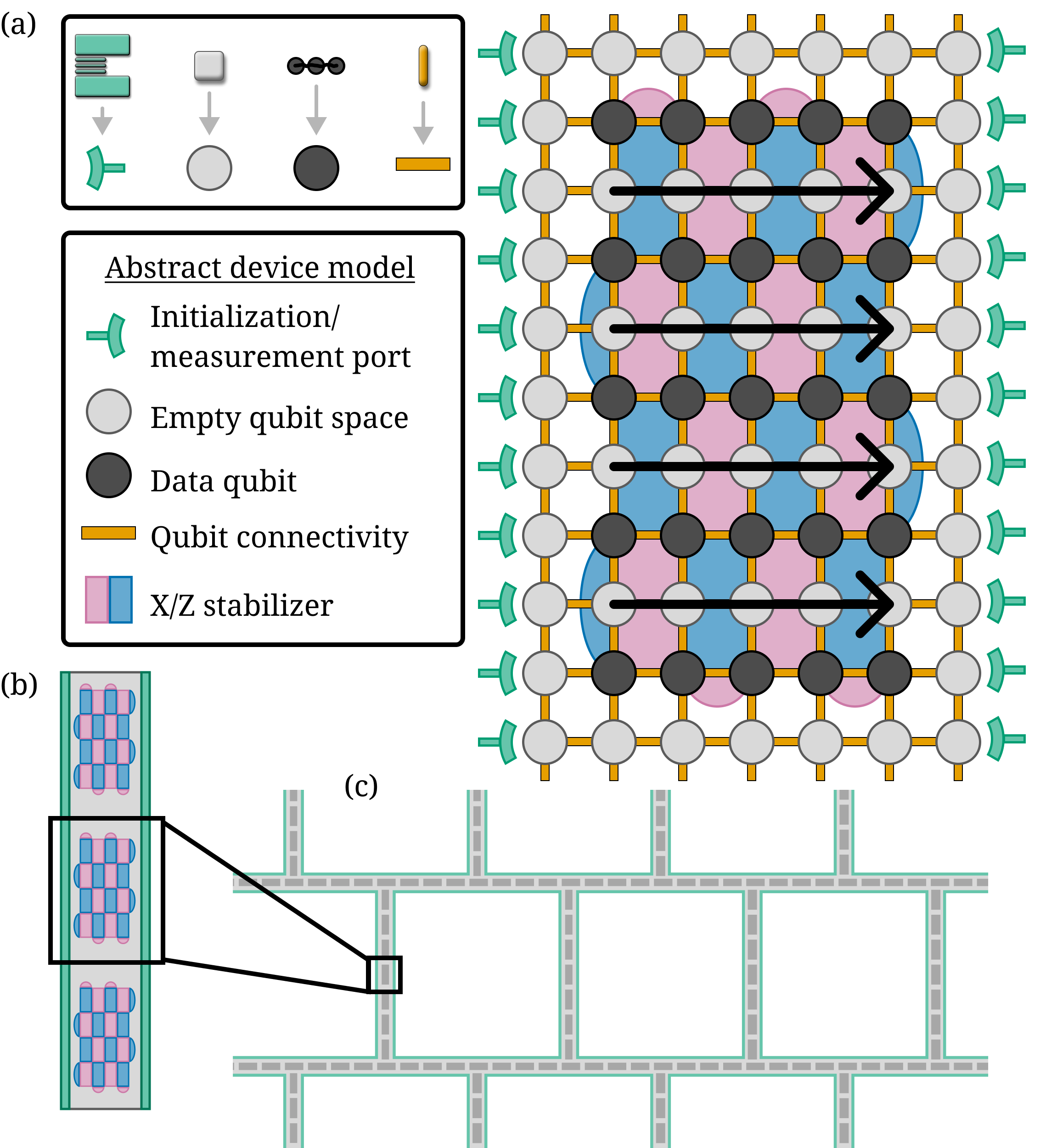
Figure 2. Proposed SNAQ (Shuttling-capable Narrow Array of spin Qubits) architecture. (a) For ease of visualization, we translate from the specific chip components in Figure 1 to the abstract components we will use in the rest of the paper. Depicted is a layout of a distance-5 surface code patch on a 7-dot-wide array. Initialization and readout components (green) are only available on the edges of the array. Data qubits (dark gray) are interleaved with channels of empty dots (light gray) used to shuttle surface code ancilla qubits from edge to edge in the direction of the black arrows. Surface code X and Z stabilizers (blue and pink) are shown behind the array, supported on the data qubits. (b) A logical 1 x N layout of surface codes in a narrow array. (c) Possible design of a fully-scalable architecture consisting of loops of SNAQ channels, with large spaces in between to allow for integration of control wires and readout.
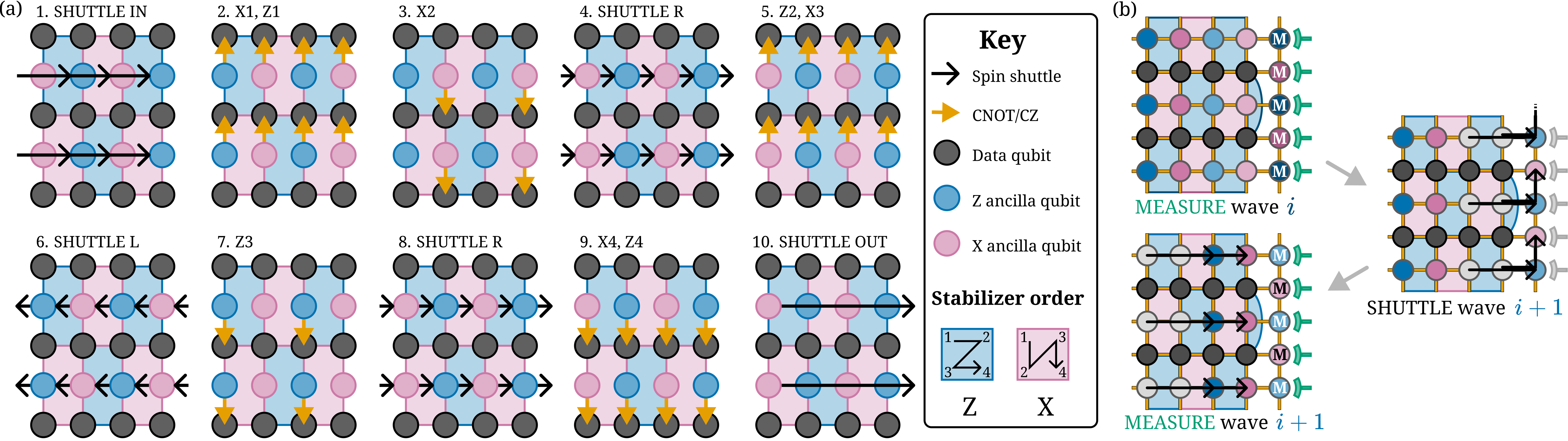
Figure 3. (a) Schedule of shuttle and CNOT/CZ operations that implement the surface code X and Z checks in the required order. Each ancilla qubit (colored circle) is responsible for interacting with four data qubits in a rectangle, and it must interact in a specific order to avoid hook errors [31], as shown in the lower right. (b) Serialized measurement of a group of ancilla qubits for readout density $\rho=1$. Ancilla qubits in group $i$ are measured first, followed by qubits in group $i+1$.
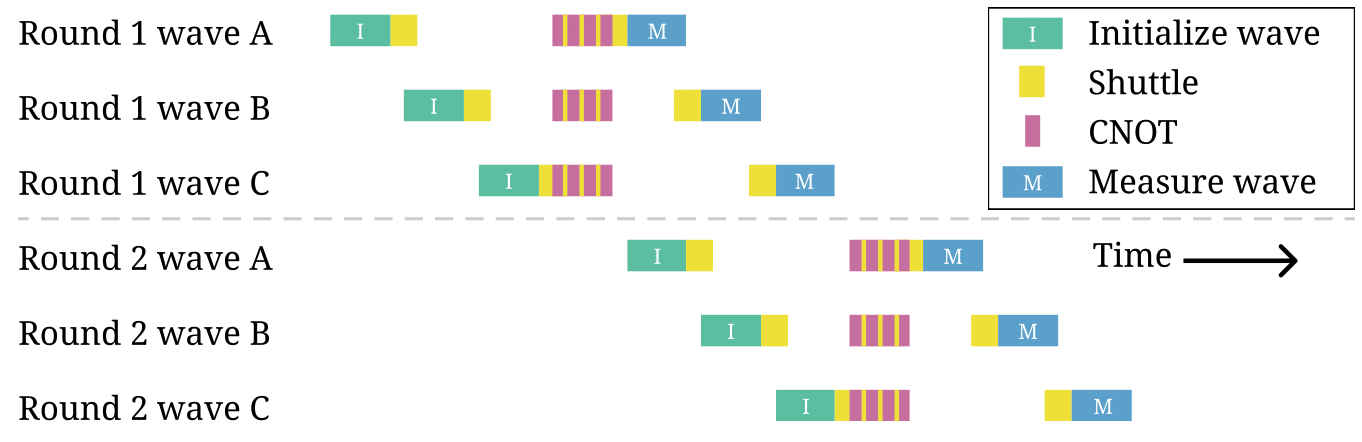
Figure 4. Example pipeline schedule showing initialization, data entanglement, and measurement for two successive rounds of ancilla qubits, split into three waves each. The measurement of the first round of ancillae can be done simultaneously with the initialization of the second round. Any blank space in the schedule indicates idling, during which dynamical decoupling techniques could be used to improve coherence.

Table 1. Comparison to prior fault-tolerant silicon architecture proposals. This summary contrasts the UnitCell and Bilinear baselines with SNAQ, highlighting our proposal’s focus on near-term manufacturability, strong low-distance performance, and efficient logical operations. Unlike the baselines, which are limited to lattice surgery (LS), SNAQ’s dense design supports fast transversal CNOTs (tCNOTs), enabling a more flexible, high-parallelism logical layout. The “1D++” logical connectivity of SNAQ refers to the potential parallelism of transversal operations compared to lattice surgery.
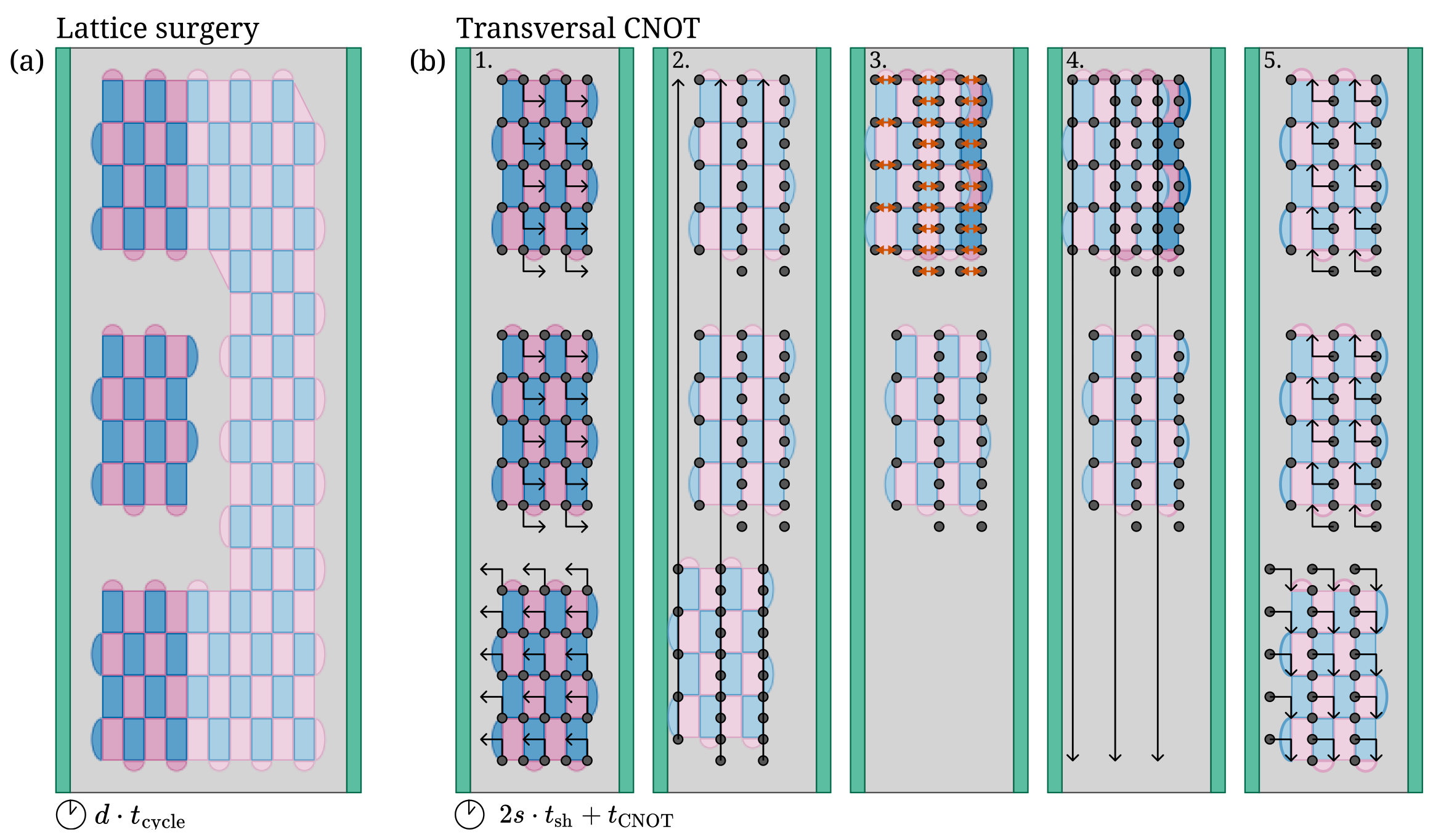
Figure 5. Two possible implementations of multiqubit operations in the SNAQ architecture. (a) Lattice surgery can connect distant logical qubits via a channel of “routing patches” (lighter shaded stabilizers), which requires a wider dot array to support a second column of surface codes. (b) Spin shuttling enables transversal CNOT operations for sufficiently-close tiles. Between stabilizer measurement rounds, physical qubits can shuttle past intermediate tiles to reach the target tile, then perform the transversal operation and shuttle back.

Figure 9. Projecting logical performance to higher code distances under fixed $(p_\text{g}, p_\text{sh}) = (10^{-3}, 10^{-5})$ for various $p_\text{id}$ with SNAQ $\rho=2$. (a) SNAQ and Bilinear give diminishing returns as code distance increases due to an increase in shuttling and idling errors with larger codeblock size, while UnitCell exhibits consistent error suppression as distance is increased. (b) Logical error rate as a function of readout count, which may be an important driver of packaging cost, showing that SNAQ outperforms Bilinear and is competitive with UnitCell. (c) Logical error rate as a function of total component area per logical qubit. For sufficiently-low $p_\text{id}$, SNAQ achieves better logical performance at significantly reduced total chip area compared to both baselines.
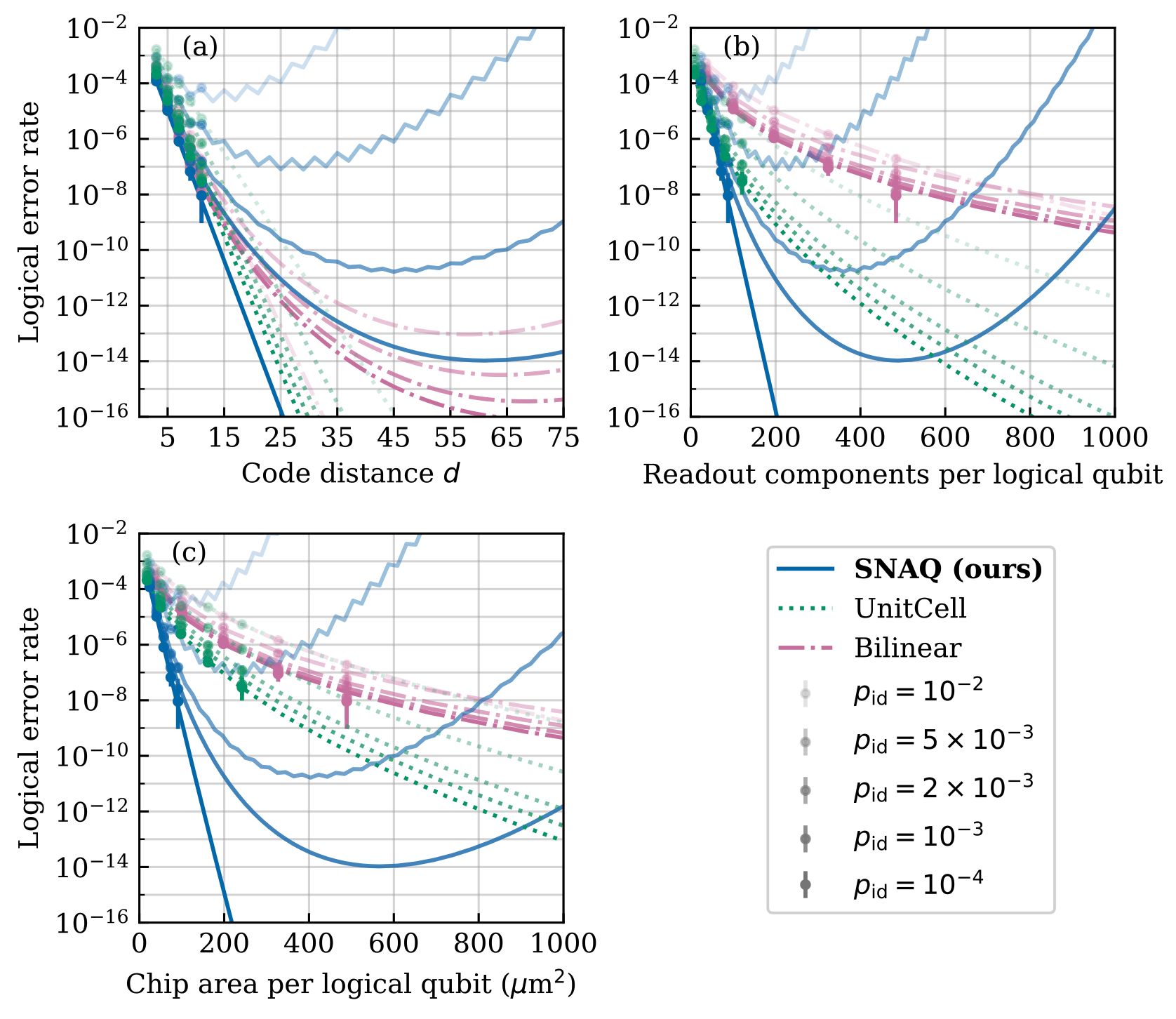
Figure 2. Proposed SNAQ (Shuttling-capable Narrow Array of spin Qubits) architecture. (a) For ease of visualization, we translate from the specific chip components in Figure 1 to the abstract components we will use in the rest of the paper. Depicted is a layout of a distance-5 surface code patch on a 7-dot-wide array. Initialization and readout components (green) are only available on the edges of the array. Data qubits (dark gray) are interleaved with channels of empty dots (light gray) used to shuttle surface code ancilla qubits from edge to edge in the direction of the black arrows. Surface code X and Z stabilizers (blue and pink) are shown behind the array, supported on the data qubits. (b) A logical 1 x N layout of surface codes in a narrow array. (c) Possible design of a fully-scalable architecture consisting of loops of SNAQ channels, with large spaces in between to allow for integration of control wires and readout.
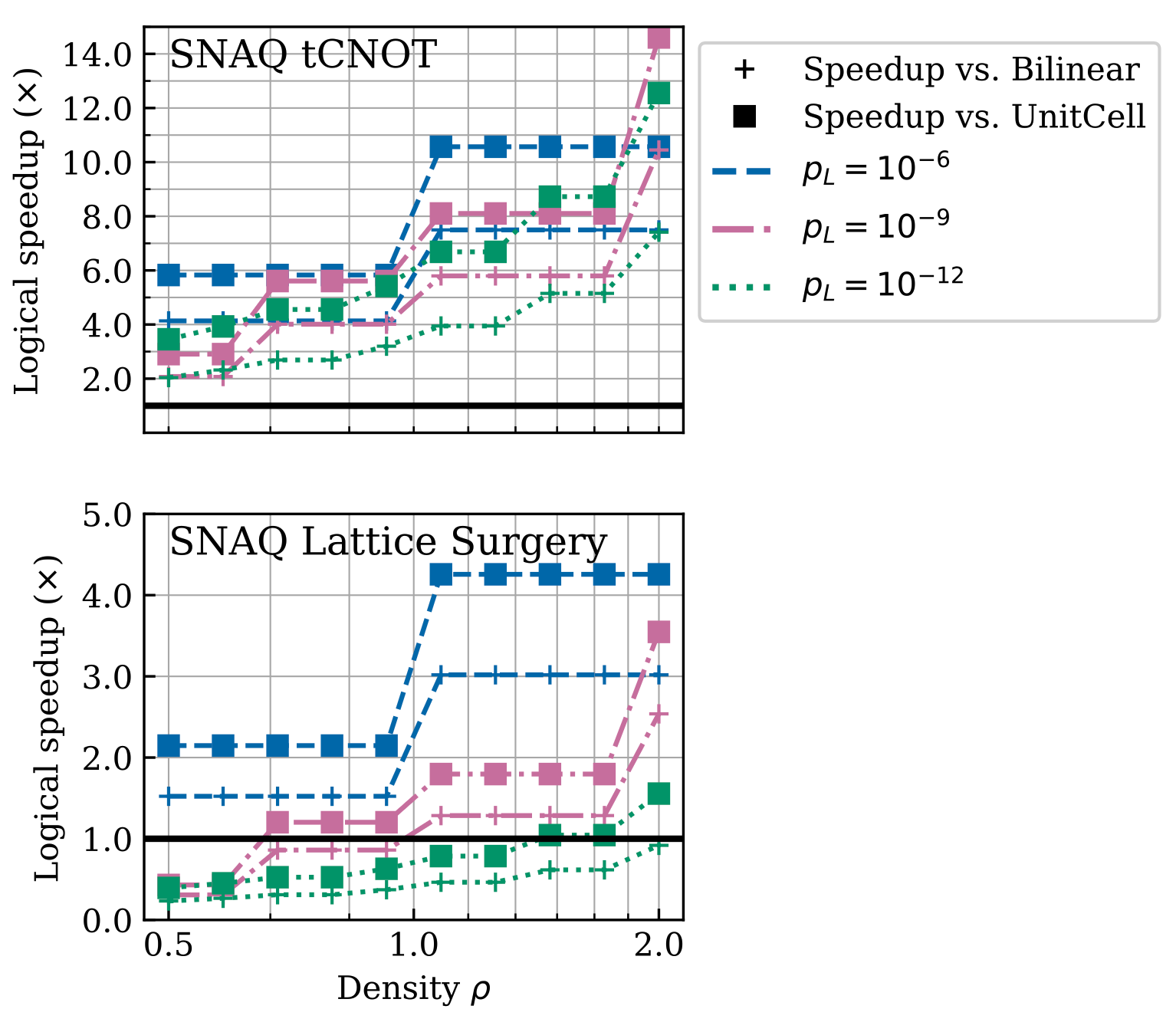
Figure 11. Comparing SNAQ logical operations to baselines under $(p_\text{g}, p_\text{sh}, p_\text{id}) = (10^{-3}, 10^{-5}, 10^{-4})$ for various $\rho.$ SNAQ’s tCNOT outperforms baseline lattice surgery methods by over 2x even for low $\rho$ and can provide up to 14.6x improvement in the range studied here. Lattice surgery on SNAQ is fast for higher $p_L$ and $\rho$, but becomes less efficient for lower $p_L$ due to the significant increase in required code distance (making each SE round take much longer).

Figure 13. Top: Logical circuit implementing 15-to-1 distillation. CNOTs are shaded in groups to show those that can be performed in parallel using transversal CNOTs. Bottom: A 2x8 SNAQ layout executing the circuit. The schedule involves parallel tCNOTs and T gate injection, interleaved with four SE rounds.

Table 2. 15-to-1 distillation cost comparison. We see that SNAQ achieves a 60-63% volume reduction compared to the baselines at $d=7$ and 64% volume reduction at $d=15$. These cost reductions, while significant, are smaller than the improvements in the logical clock speed. We attribute this to two aspects of this particular example: (1) the compiled distillation circuit is very shallow, with only five layers of tCNOTs, so placing an SE round after every two tCNOTs yields an average SE count per tCNOT of 0.8 instead of the 0.5 we would aim for in a deep circuit, and (2) the double-column logical layout, which was chosen to reduce shuttling distance, makes each SE round twice as slow.
My Contributions
← back to jason-chadwick.com