Qompress: Efficient Compilation for Ququarts Exploiting Partial and Mixed Radix Operations for Communication Reduction
International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2023)
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
University of Chicago
Abstract
Quantum computing is in an era of limited resources. Current hardware lacks high fidelity gates, long coherence times, and the number of computational units required to perform meaningful computation. Current quantum devices typically use a binary system, where each qubit exists in a superposition of the $\ket 0$ and $\ket 1$ states. However, it is often possible to access the $\ket 2$ or even $\ket 3$ states in these same physical unit by manipulating the system in different ways. In this work, we consider automatically encoding two qubits into one four-state ququart via a compression scheme. We use quantum optimal control to design efficient proof-of-concept gates that fully replicate standard qubit computation on these encoded qubits.
We extend qubit compilation schemes to efficiently route qubits on an arbitrary mixed-radix system consisting of both qubits and ququarts, reducing communication and minimizing excess circuit execution time introduced by longer-duration ququart gates. In conjunction with these compilation strategies, we introduce several methods to find beneficial compressions, reducing circuit error due to computation and communication by up to 50%. These methods can increase the computational space available on a limited near-term machine by up to 2x while maintaining circuit fidelity.
[.pdf] [publication] [arXiv]Selected Figures
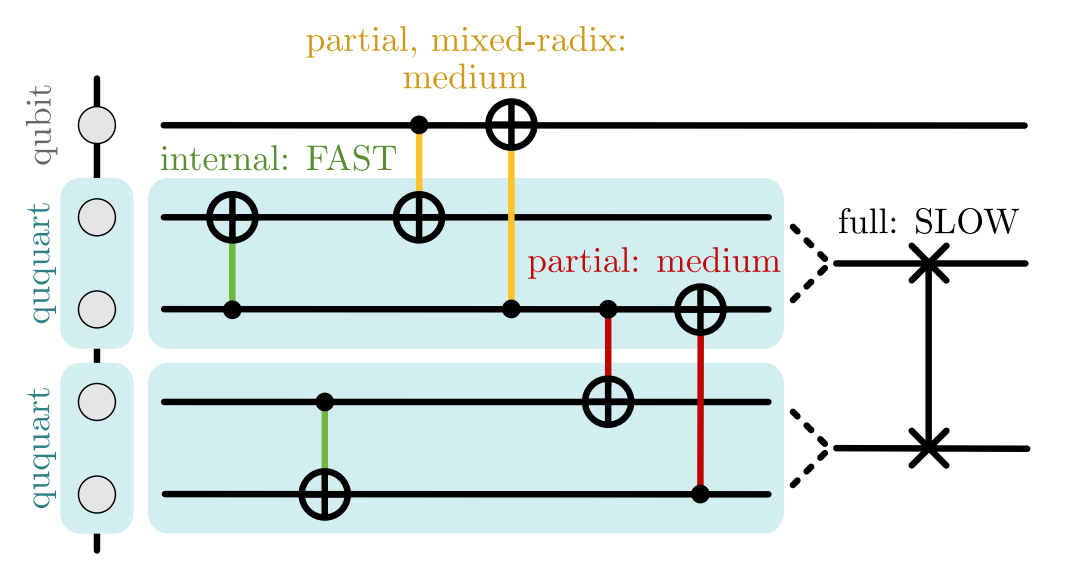
Figure 1: Pairs of qubits can be compressed in fourdimensional ququarts and interact with each other internally or through partial operations, enabling novel compilation techniques and space reduction.
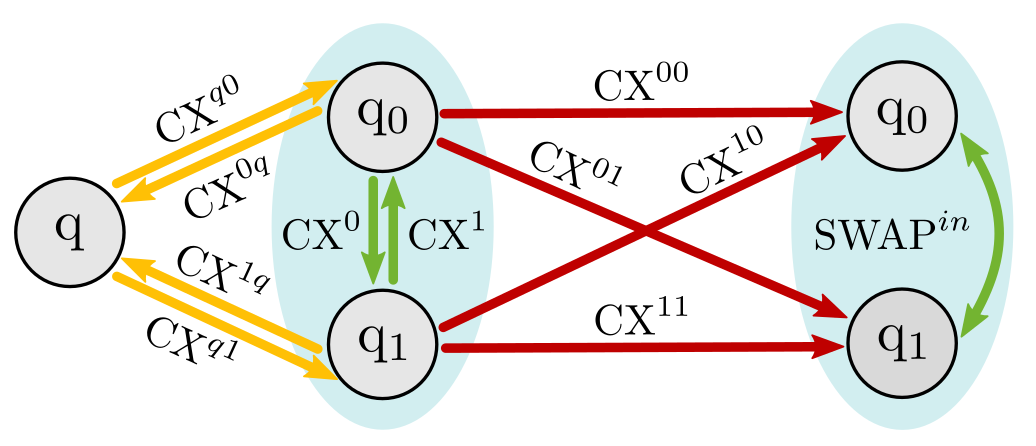
Figure 2. Two qubits $q_0$ and $q_1$ can be encoded into a ququart (blue oval) and interact with each other internally (green), with bare qubit $q$ outside (yellow), or with encoded qubits in a different ququart (red). CX arrows point from control qubit to target qubit. Along each CX link, corresponding SWAP gates are defined with the same superscripts/subscripts (not shown).
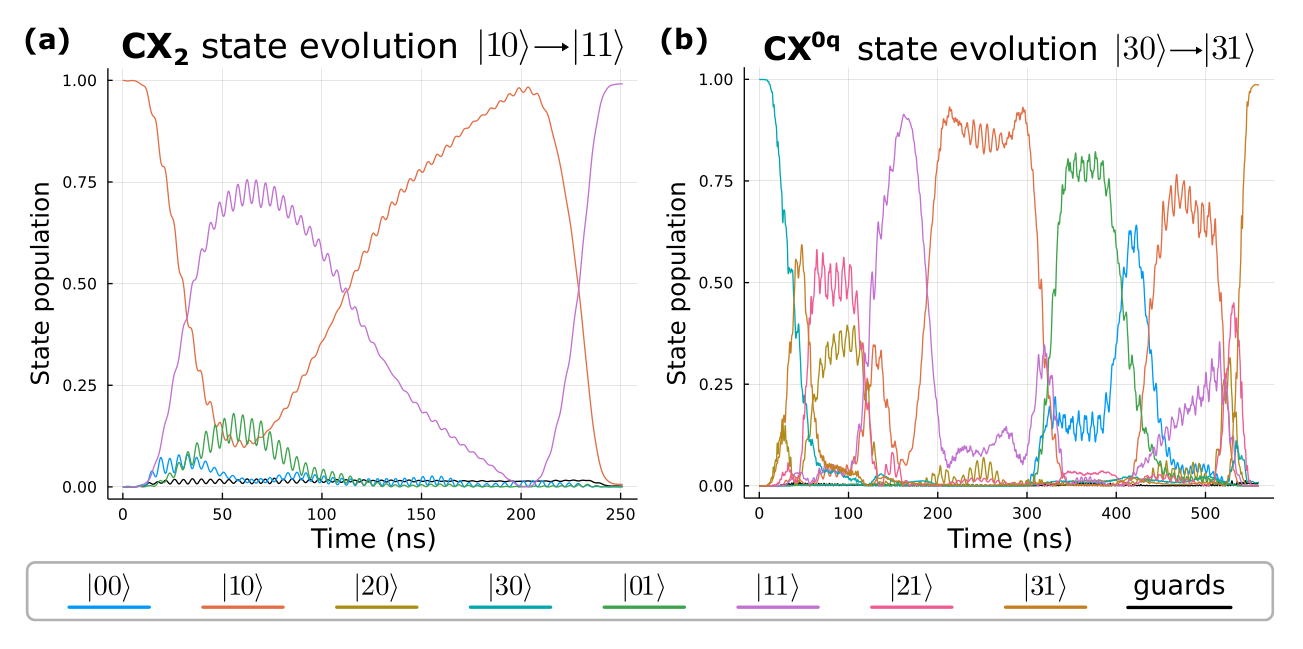
Figure 3. Exemplary state evolutions of two CX gates between (a) two bare qubits and (b) a bare qubit and an encoded qubit. (a) The control qubit $q_0$ is in state $\ket{1}$, hence the state of the target qubit $q_1$ is flipped. (b) The encoded qubit $q_0$ inside the ququart controls the CX gate targeting the bare qubit $q$. The ququart state $\ket{3}$ corresponds to the two-qubit state $\ket{q_0 q_1} = \ket{11}$, so the state of $q$ is flipped.
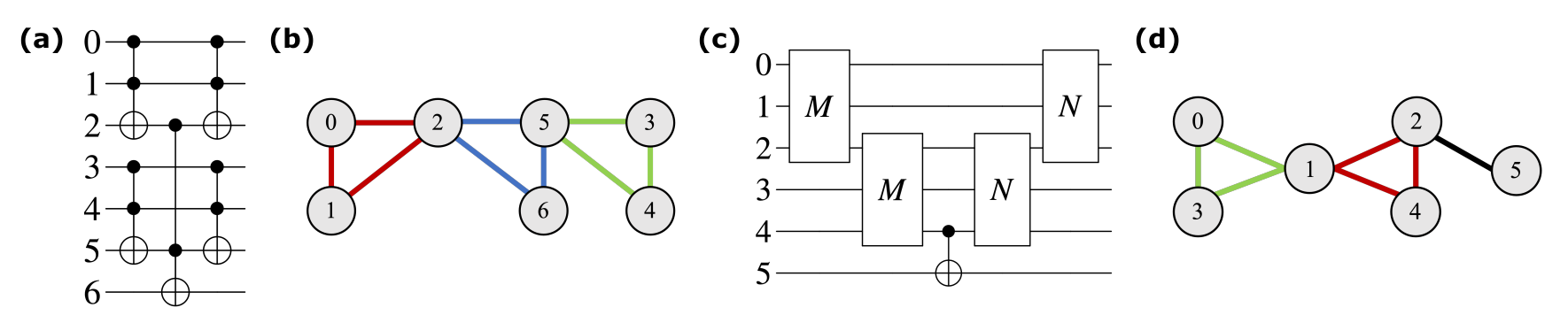
Figure 5. (a), (b) Sample generalized Toffoli gate with corresponding interaction graph. (c), (d) Cuccaro adder with interaction graph, M and N are three qubit gate blocks. Some circuits, such as the CNU circuit and Cuccaro Adder have clusters of qubits that interact with one another. These clusters can be identified by finding the cycles in the interaction graph. We have identified the cycles here with colored edges.
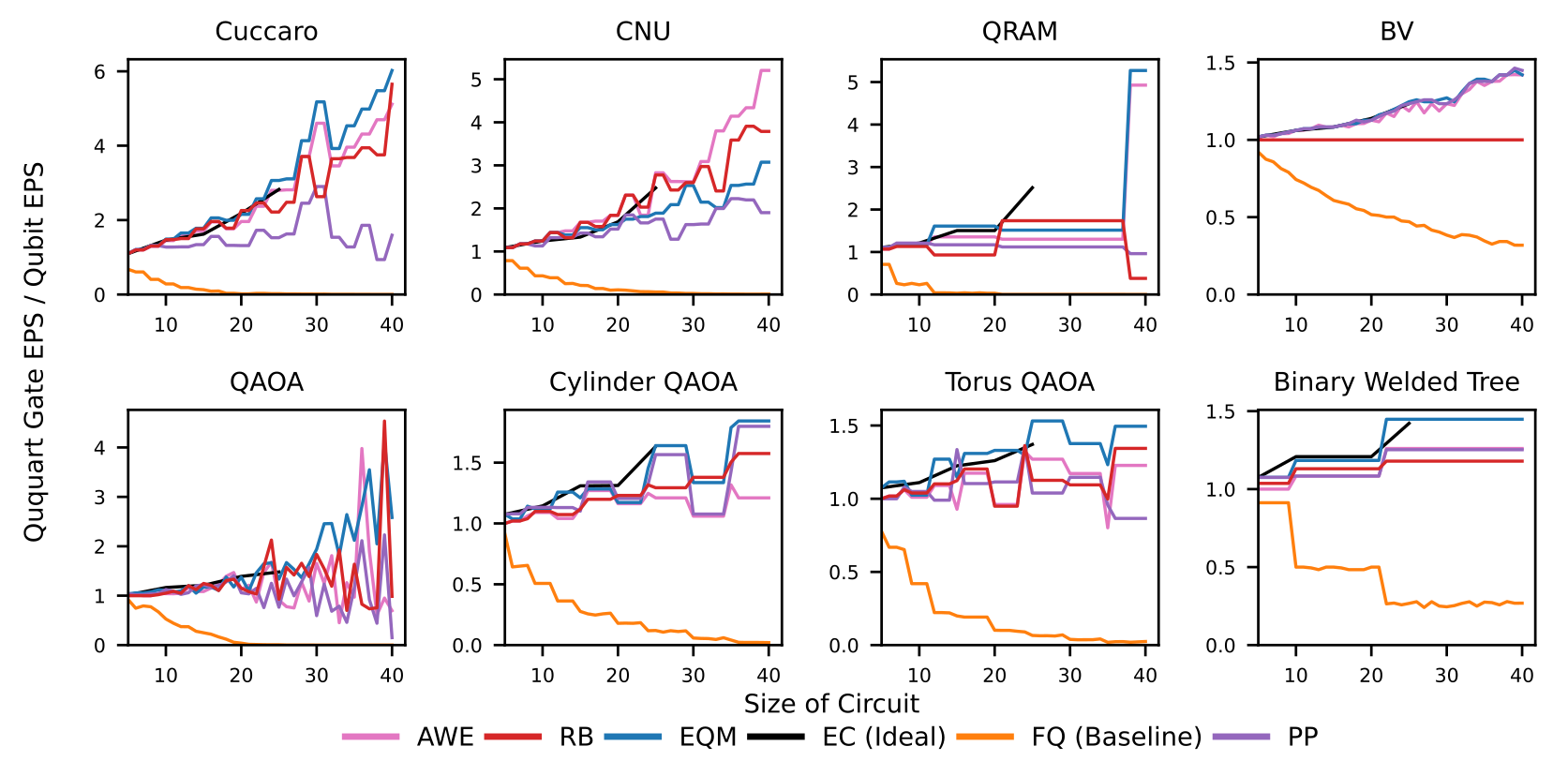
Figure 7. Expected Gate Probability of Success for each benchmark. Each color represents a a different compilation strategy, where the black line is the exhaustive solution developed previously, and is the goal. FQ is the previous baseline for generalized ququart computation.
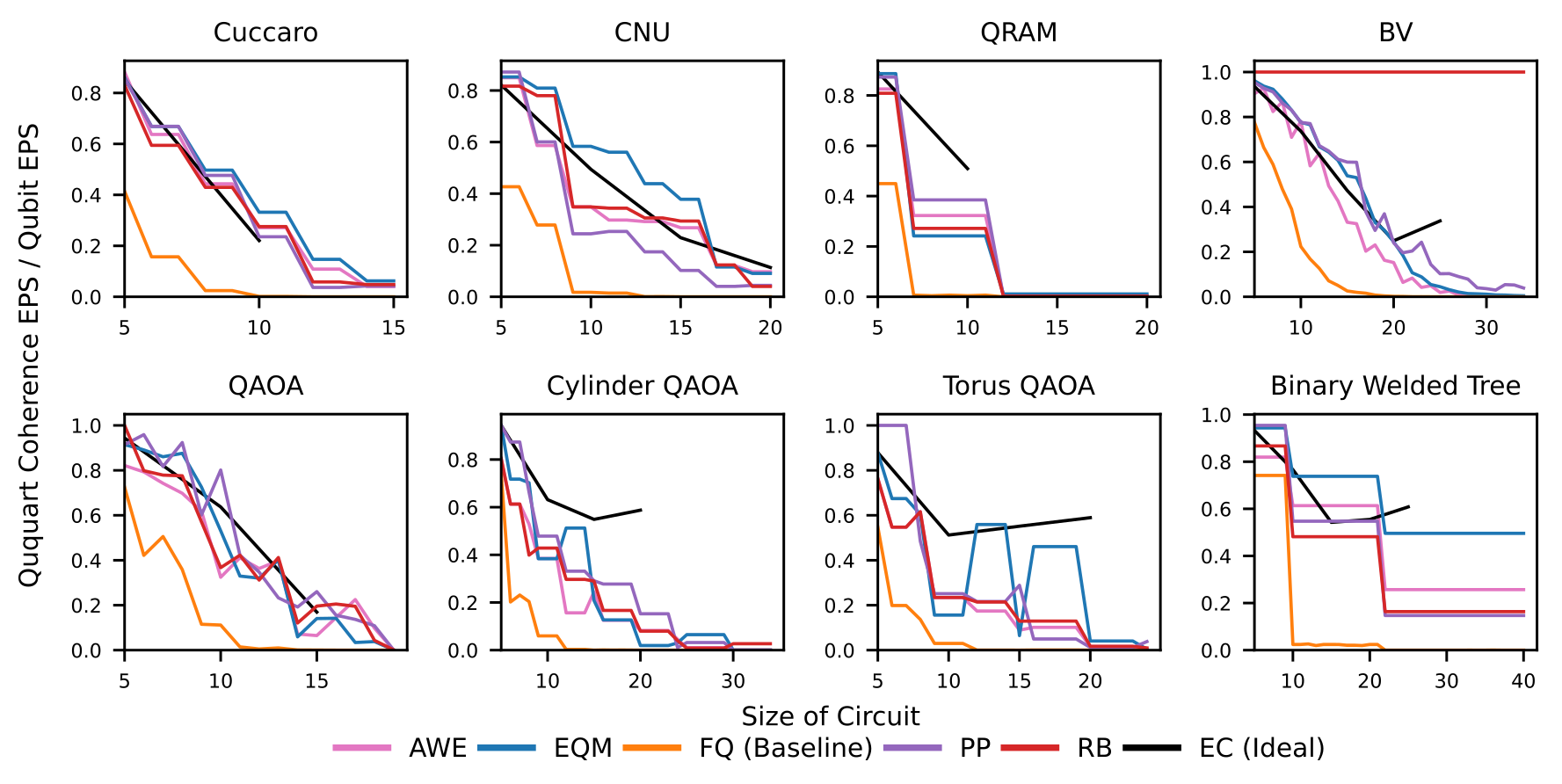
Figure 10. Expected Coherence Probability of Success for each benchmark. Each color represents a a different compilation strategy, where the black line is the exhaustive solution developed previously, and is the goal. EC line stops short for computational reasons, requiring many more classical resources. FQ is the previous baseline for generalized ququart computation.
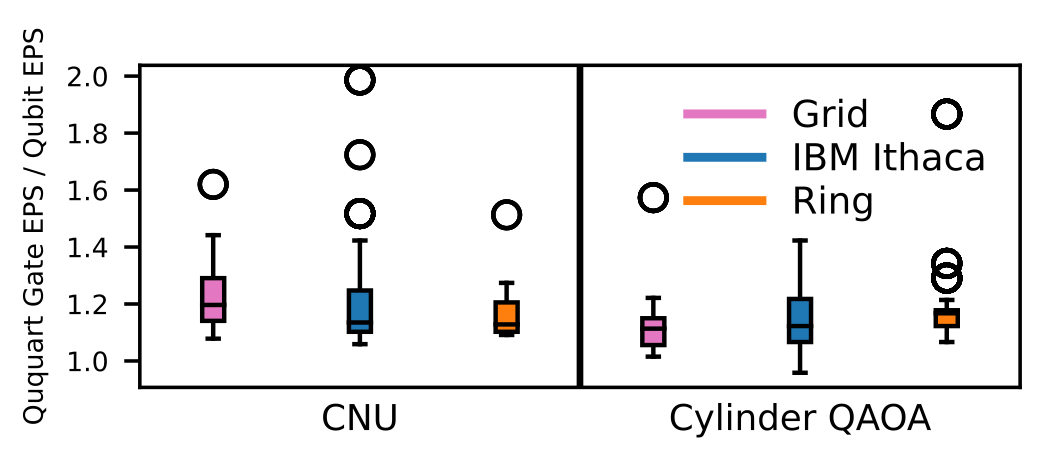
Figure 13. Ranges of gate based probability of success for CNU and Cylinder QAOA on three different architectural topologies. These is the combined set of ratios of improvement for circuits sizes 5 to 40.
My Contributions
← back to jason-chadwick.com